

Hoofdstuk 10: ANOVA: One-Way Analysis of Variance (final) *
 Enkelvoudige variantieanalyse: model en aannames
Enkelvoudige variantieanalyse: model en aannames
Het model voor enkelvoudige variantieanalyse
Het statistische model dat als basis dient voor de procedure van de enkelvoudige variantieanalyse wordt gegeven door:
\[Y_i = \mu_i + \varepsilon\]
Hier geldt het volgende.
- #Y_i# is de waarde van de uitkomstvariabele #Y# voor een willekeurig geselecteerde observatie uit de populatie #i#.
- #\mu_i# is het populatiegemiddelde voor de uitkomstvariabele #Y# voor niveau #i#.
- #\varepsilon# wordt de fout genoemd, waarmee we de mate bedoelen waarin de waarde van #Y# afwijkt van #\mu_i# voor een willekeurig geselecteerde observatie uit de populatie #i#.
Aannames van een enkelvoudige variantieanalyse
Er moet aan de volgende aannames worden voldaan voordat het model voor enkelvoudig variantieanalyse geldige resultaten oplevert:
- De afhankelijke variabele is normaal verdeeld in elk van de #i# populaties die worden vergeleken.
- Homogeniteit van varianties (homoscedasticiteit), wat betekent dat de populatievariantie voor alle populaties hetzelfde is.
- De waarnemingen moeten onafhankelijk zijn, wat betekent:
- Willekeurige steekproeven worden getrokken uit de populaties.
- Geen enkele waarneming kan deel uitmaken van meer dan één steekproef.
- Er is geen relatie tussen de waarnemingen binnen elke steekproef of tussen de steekproeven.
- Willekeurige steekproeven worden getrokken uit de populaties.
Zowel de aanname van normaliteit als de aanname van homogeniteit kunnen worden gecontroleerd door de residuen van het model te analyseren.
Voor het model wordt een residu #e_{ij}# gedefinieerd als het verschil tussen een waargenomen waarde #Y_{ij}# en het steekproefgemiddelde #\bar{Y}_i# :
\[e_{ij} = Y_{ij} - \bar{Y}_i\] Als de residuen normaal verdeeld zijn en de variantie van de residuen in alle steekproeven hetzelfde is, kunnen we erop vertrouwen dat de aannames van normaliteit en homogeniteit ook gelden voor de onderliggende populaties.
De aanname van onafhankelijke observaties is afhankelijk van de vraag of de gegevensverzameling op de juiste manier is uitgevoerd, en er moet dus aan worden voldaan door middel van goede onderzoeksontwerpen.
Om informeel te controleren of aan de aanname van normaliteit is voldaan, kunnen we een Q-Q plot voor de residuen construeren. Hierbij is Q-Q een afkorting van het Engelse quantile-quantile.
Q-Q plot De (normale) Q-Q plot voor de residuen is een spreidingsdiagram dat wordt gecreëerd door de kwantielen van de residuen uit te zetten tegen de theoretische kwantielen van de standaardnormale verdeling.
Als de aanname van normaliteit klopt, zouden we moeten zien dat de punten ruwweg een rechte lijn vormen.
De volgende Q-Q plot van de residuen toont een goede overeenkomst tussen de kwantielen van de residuen en de theoretische kwantielen van de standaardnormale verdeling:
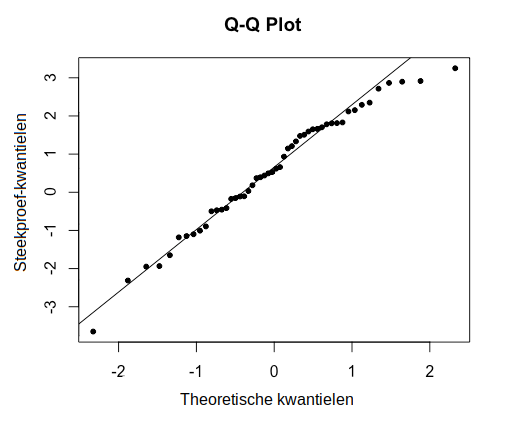
De volgende twee Q-Q plots laten een duidelijke afwijking van normaliteit zien:
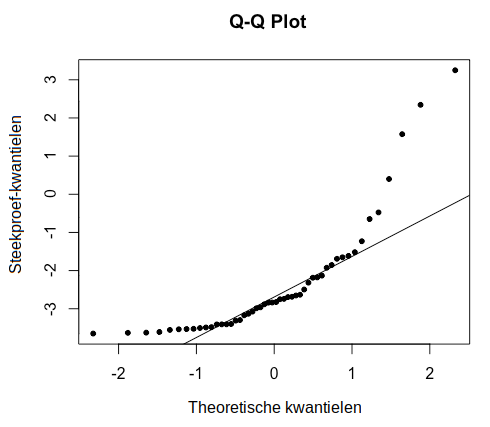
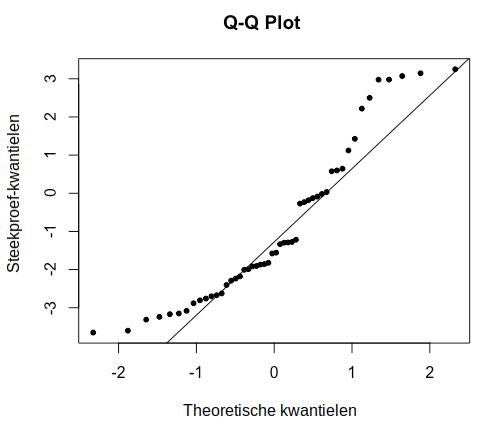
Om formeel te controleren of aan de aanname van normaliteit is voldaan, kunnen we de Shapiro-Wilk toets voor normaliteit uitvoeren.
Shapiro-Wilk-toets voor normaliteit
De Shapiro-Wilk-toets voor normaliteit heeft de volgende hypothesen:
\[\begin{array}{rcl}
H_0 &:& \text{De residuen zijn normaal verdeeld.}\\\\
H_a &:& \text{De residuen zijn niet normaal verdeeld.}
\end{array}\]
Een kleine #p#-waarde geeft dus aan dat de residuen niet normaal verdeeld zijn, wat op zijn beurt impliceert dat de afhankelijke variabele niet normaal verdeeld is in elke populatie die wordt vergeleken.
Als de aanname van normaliteit wordt geschonden, zal elke conclusie op basis van deze aanname ongeldig zijn.
Om informeel te controleren of aan de aanname van homogeniteit van varianties is voldaan, kunnen we een residuenplot construeren.
Residuenplot
Een residuenplot is een spreidingsdiagram van de residuen #e_{ij}# tegen de steekproefgemiddelden #\bar{Y}_i#.
Als de aanname van homogeniteit van varianties geldt, zou de residuenplot voor elk waargenomen steekproefgemiddelde ongeveer dezelfde spreiding moeten laten zien, en geen extreme uitschieters.
Beschouw de volgende residuenplot:
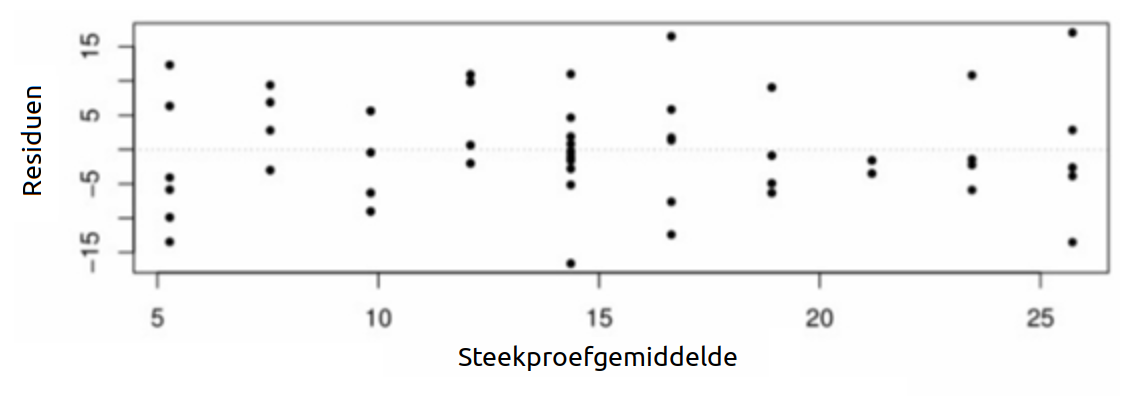 We zien dat de punten verspreid zijn tussen #-15# en #15# over het volledige bereik van de steekproefgemiddelden, zonder dat er een patroon zichtbaar is. Bovendien lijkt de variantie van de residuen niet afhankelijk te zijn van de waarde van de onafhankelijke variabele, dat wil zeggen dat we homoscedasticiteit hebben.
We zien dat de punten verspreid zijn tussen #-15# en #15# over het volledige bereik van de steekproefgemiddelden, zonder dat er een patroon zichtbaar is. Bovendien lijkt de variantie van de residuen niet afhankelijk te zijn van de waarde van de onafhankelijke variabele, dat wil zeggen dat we homoscedasticiteit hebben.
Daarentegen toont de volgende residuenplot duidelijk bewijs van heteroscedasticiteit:
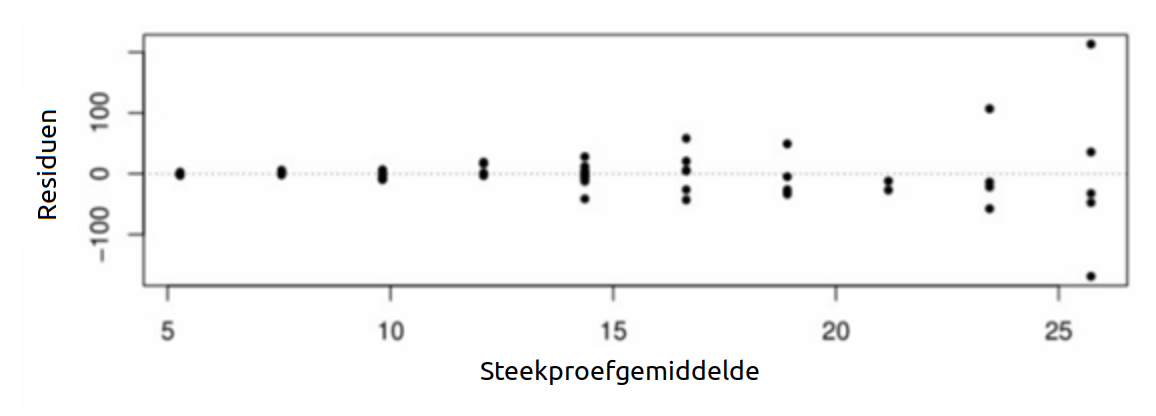 Hier zien we dat de verticale spreiding van de residuen groter wordt naarmate de steekproefgemiddelden toenemen, wat het duidelijk maakt dat de variantie niet constant is, maar afhangt van het niveau van de factor. Dit maakt elke statistische conclusie die we zouden kunnen trekken op basis van het variantieanalyse-model ongeldig.
Hier zien we dat de verticale spreiding van de residuen groter wordt naarmate de steekproefgemiddelden toenemen, wat het duidelijk maakt dat de variantie niet constant is, maar afhangt van het niveau van de factor. Dit maakt elke statistische conclusie die we zouden kunnen trekken op basis van het variantieanalyse-model ongeldig.
In het bovenstaande diagram zie je dat er een correlatie bestaat tussen de omvang van de residuen en de steekproefgemiddelden, dat wil zeggen: hoe groter het steekproefgemiddelde, hoe groter de gemiddelde omvang van de residuen.
Om formeel te controleren of aan de aanname van homogeniteit van varianties al dan niet is voldaan, kunnen we Levene's toets of Bartlett's toets uitvoeren.
Levene's toets en Bartlett's toets
Zowel de Levene's toets als de Bartlett's toets hebben de volgende hypothesen:
\[\begin{array}{rcl}
H_0 &:& \text{Alle populatievarianties zijn gelijk.}\\\\
H_a &:& \text{Ten minste twee populatievarianties verschillen van elkaar.}
\end{array}\]
Een kleine #p#-waarde impliceert dus dat de aanname van homogeniteit van varianties is geschonden, en maakt daardoor elke conclusie op basis van deze aanname ongeldig.
Van deze twee toetsen is Levene's toets het minst gevoelig voor afwijkingen van de normaliteit en moet deze worden gebruikt wanneer de aanname van normaliteit wordt geschonden. Als echter aan de aanname van normaliteit wordt voldaan, heeft Bartlett's toets een groter onderscheidend vermogen.

omptest.org als je een OMPT examen moet maken.

